type
status
date
slug
summary
tags
category
icon
password
Property
Aug 31, 2022 04:53 AM
URL
DETR参考CSDNblog的代码注释,主要是进transformer之前的数据处理。
CSDN
来源:


源码获取:https://gitee.com/fgy120/DETR
首先对 DETR 做个简单介绍
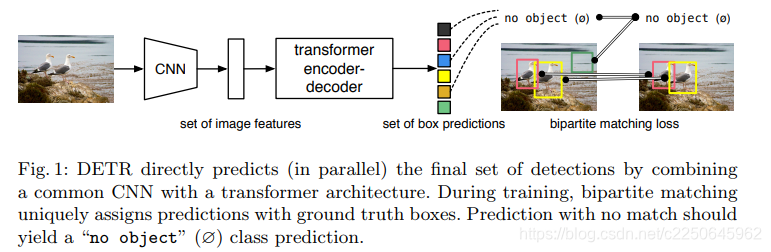
上图即为 DETR 的流程 pipeline,相比以前的 RCNN 系列、YOLO 系列等,最特别的在于加入了 Transformer。
目录
main 函数(一)参数设置
直接看源码,从 train.py 的主函数开始。
首先是常规的参数解析操作,利用的 argparse 库,主要通过解析命令行输入的参数来设置模型训练的超参数或其他设置。第一步创建解析对象 parser,运行 parser.parse_args 方法得到解析后的各个参数 args,默认为解析运行代码的命令行。如果其中包含 output_dir 参数且 output_dir 不存在,利用 Pathlib 中的 Path 库的 mkdir 方法创建 output_dir 的路径文件夹。
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
parents:如果父目录不存在,是否创建父目录。
exist_ok:只有在目录不存在时创建目录,目录已存在时不会抛出异常。
argparse 具体介绍可以看这篇。argparse 解析器
更新后新的参数设置如下:
接着进入 main() 函数
utils.init_distributed_mode(args):判断是否进行分布式训练,根据你的电脑的环境配置中是否有相关配置来判断或设置,一般单卡单机的话都是执行到 else 语句就 return 了。
上述第一个if是用来做多节点的,rank是进程序号,world_wise是进程数量,local_rank是当前进程占用的gpu,第二个if是用slurm做多机协同多卡,最后使用torch.distributed部署,该接口比torch.nn.DataParallel事实证明要好,详细参考PyTorch 多进程分布式训练实战 | 拾荒志 或者PyTorch 多进程分布式训练实战 | 拾荒志 (murphypei.github.io)
utils.get_sha():通过命令行获得git 的commitID和git status以及所在的branch。
subprocess.check_output(command, cwd=cwd) subprocess库的check_output方法通过在cwd打开cmd,然后输入commend,并返回cmd的输出
device = torch.device(args.device)#选择cuda或者cpu,通过解析得到device的参数来决定tensor分配到的设备是GPU还是CPU
seed = args.seed + utils.get_rank() #utils.get_rank()当分布式训练时,需要多个seed torch.manual_seed(seed) np.random.seed(seed) random.seed(seed) seed会决定上面三种取随机数方法的值,相同的随机种子seed将模型在初始化过程中所用到的“随机数”全部固定下来,即每次初始化都是一样的,以保证每次重新训练模型需要初始化模型参数的时候能够得到相同的初始化参数,从而达到稳定复现训练结果的目的。
main 函数(二)搭建模型
pytorch遍历参数修改属性
- model.named_parameters()
return: 返回model的所有参数的(name, tensor)的键值对。可以修改参数的requires_grad属性。用法: 常用于对网络的参数进行一些特殊的处理(比如 fine-tuning)。
- model.parameters()
return: 返回model的所有参数的tensor。可以修改参数的requires_grad属性。用法: 主要提供给optimizer。
- model.state_dict()
return: 返回model的参数的(name, tensor)的键值对字典,参数的requires_grad=false,不可以修改参数的requires_grad属性。用法: 常用于保存模型和加载模型的时候使用。
detr模型main中搭建调用、优化器、数据集等设置
网络搭建函数细节
model, criterion, postprocessors = build_model(args)构建网络模型
build(args):
build_backbone():包括构建位置编码器以及 backbone
build_position_encoding(args): 构建位置编码器,有两种方式,一种是使用正、余弦函数来对各位置的奇、偶维度进行编码,不需要额外的参数进行学习,DETR默认使用的就是这种正余弦编码。还有一种是可学习的。下面主要讲解正余弦编码
PositionEmbeddingSine(N_steps, normalize=True):正余弦编码方式,这种方式是将各个位置的各个维度映射到角度上,因此有个scale,默认是2pi。下面的是编码公式
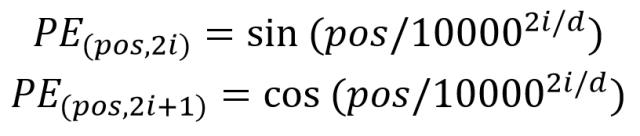
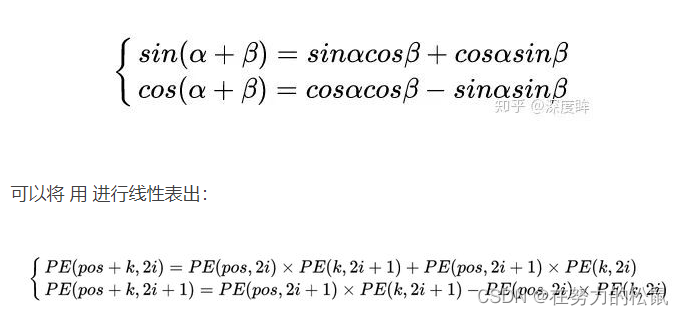
得到位置编码 pos,pos 是一个(batch, 2* num_post_feats, height, width)的 tensor,每个 batch 中的每一个前 num_post_feats 的(height, width)tensor 表示 y 方向的位置编码 pos_y, 后 num_post_feats 则表示 x 方向的位置编码,合并使用则可以得到类似(pos_y,pos_x)的效果来对 2D 张量进行位置编码
build_position 得到位置编码后回到接下来回到 build_backbone 函数
args.lr_backbone 默认为 1e-5,则 train_backbone 默认为 true,通过设置 backbone 的 lr 来设置是否训练网络时接收 backbone 的梯度从而让 backbone 也训练。return_interm_layers 在后面解释。进入到 Backbone() 函数,args.backbone 默认为 resnet50,args.dilatyion 默认为 false。
获得 resnet50 网络结构,并设置输出 channels 为 2048,所以我们的 backbone 的输出则是 (batch,2048,H//32,W//32),在父类 BackboneBase.__init__中进行初始化。
到这,位置编码和 backbone 都搭建完毕,回到 build_backbone
接着在 Joiner()中,将 backbone 和位置编码器用 nn.Sequential() 按顺序结合,forward 可结合前面的一起来看,过一遍操作
backbone 搭建完成后,回到 build(args),接下来是搭建 transformer,就在 DETR 源码笔记(二)吧 。 > 本文由简悦 SimpRead 转码
Mask的解释
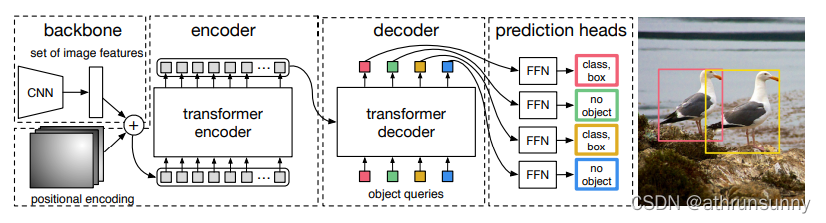
按照训练流程首先介绍 backbone 以及数据进入 encoder 之前的部分
当训练时,使用 torch.manual_seed(seed) 函数,只要网络参数不变的情况下,网络的参数初始化每次都是固定的;如果没有设置,每次训练时的初始化都是随机的,导致结果不确定。
例如:要训练自己的数据集通常需要对 num_classes 进行设置。(其中 num_classes 的设置根据自己数据集类别数量 + 1,也就是说,假设 coco 的数据集中总共有 90 个类,此时的 num_classes 就是 91)
假设刚开始设置的 num_classes=5,那么只要训练过程中网络的参数不变,那么网络的初始化参数都是一样的;如果下次训练时 num_classes=6,最直观的变化就是数据集中图像的读取顺序发生了变化,并且由于训练时有对图像进行随机拉伸,也就导致参数变化后,同一张图像在上一次训练时的尺寸和当前训练尺寸不一。
backbone 调用的是 torchvision 中定义的 resnet50,这里的 backbone 也就是送入 transformer 之前用来提取图像特征图的骨架,所以张量在经过 resnet50 的卷积后得到的特征图通道数由原来的 3 通道变为 2048,WH = W/32 H/32,具体来说,假设一开始输入的张量是由 batch size 为 2,长宽都为 768 组成的 3 通道图像,即 [b, c, h, w] = [2,3,768,768],经过 resnet50 后,shape 变为 [2,2048,24,24]。
具体的代码如下:
还是假设输入为 [b, c, h, w] = [2,3,768,768] 的张量(没有特殊声明的话后面提到的张量也是基于 [2,3,768,768] 的计算得来),通过 resnet50 得到 [2,2048,24,24] 的张量(这个张量也称为 Feature Map)后需要对原始输入中的 mask 进行相应的 reshape,mask 其实是在 dataloader 生成时,原始输入中原始图像位置的映射。
怎么解释这个 “原始输入中原始图像位置的映射” 呢?
由于生成数据时对数据集中图像进行随机 load,再加上对图像进行随机裁剪,所以同一 batch 的数据尺寸存在差异,但是同一 batch 输入 resnet 的大小需要保持一致,就需要对图像进行 padding(全 0)操作以保证同一 batch 的尺寸相同。具体来说就是找到该 batch 下最大的 W 和最大的 H,然后 batch 下所有的图像根据这个最大的 W*H 进行 padding。
而 mask 就是为了记录未 padding 前的原始图像在 padding 后的图像中的位置。举例来说就是假设 batch 为 2,其中一张图像的 wh=768768,另一张图像的 wh 为 576580,这个最大的 W 和 H 就是 768。生成大小为 [768,786] 全 0 的张量,而较小的图像填充在这全 0 张量的左上角,也就是说张量中 [576:768] 以及 [580:768] 的部分都为 0,反应在 mask 上就是 [0:580,0:576] 的部分为 False,表示未被 padding 部分,[576:768]以及 [580:768] 的部分为 True,表示被 padding 部分。效果如下图:
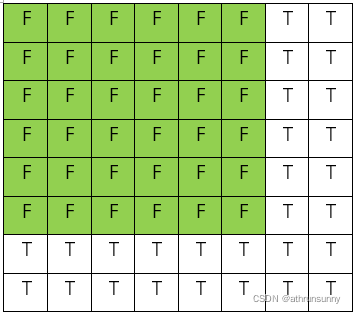
具体操作见如下代码:
mask 按照 Feature Map 的 h 和 w 进行 reshape,即原始输入中的 mask 为 [2,768,768],将其 shape 变为 [2,24,24],最终输出的 out 为 {mask,[2,24,24],tensor_list,[2,2048,24,24]}。得到 out 之后,就需要根据 Transformer 所需要的数据结构,将 out 转化为能够被 Transformer Encoder 处理的序列化数据。如位置编码,降维,shape 转换。
首先是位置编码,也就是 position encoding(PE),这里的位置编码是基于 out 中的 mask,也就是 [2,24,24] 进行的。算法类似于最初在《Attention is all you need》中提出的 PE,这里只是将位置编码作用于图像中。最后输出编码后的位置信息,shape 为[2,256,24,24]。
再者是降维,在数据送入 transformer 之前,即:
需要将 backbone 网络输出的 Feature Map 使用 1x1 的线性层降维,得到与 mask 相同的 channel,即 [2,256,24,24]
最后是 reshape,将降维后的 H 和 W 维度合并,然后进行维度转化 [NxCxHxW]->[HWxNxC], 即 [2,256,24,24]->[576,2,256],此时输入 transformer 的 Feature Map 的 shape 转换为 [576,2,256],同时由 mask 生成的位置编码(pos)维度也转化为 [576,2,256]。词嵌入向量由 [num_embeddings, embedding_dim]->[num_embeddings, N, embedding_dim],即 [100,256]->[100,2,256]( 对于 torch.nn.Embedding 的理解可以看这篇文章),mask 的也将 H 和 W 维度合并,shape 由 [2,24,24] 转化为[2,576]。
到这里大致把输入 transformer 之前的数据处理过程理清,接下来是 transformer 部分,不了解 transformer 的可以看一下我的另一篇文章 transformer 学习笔记。与 NLP 中的 transformer 有一定的区别,具体可见 DETR 代码学习笔记(二)。 > 本文由简悦 SimpRead 转码